手把手教会你如何通过ChatGPT API实现上下文对话

Contents
前言
ChatGPT最近热度持续高涨,已经成为互联网和金融投资领域最热门的话题。
有的小伙伴可能需要在公司搭建一套ChatGPT系统,那使用ChatGPT的API显然是最好的选择。
不过ChatGPT的API都是无状态的,没有对话管理的功能。
你调用API发送一个问题(prompt)给ChatGPT,它就根据你发送的问题返回一个结果(completion)。
那如何通过ChatGPT的API实现带上下文功能的对话呢。
ChatGPT API
ChatGPT的API实际上是对标准的HTTP接口做了一层封装,HTTP请求的url地址如下:
官方封装了Python和Node.js库,可以直接使用。
我们来看一段Python代码示例:
|
|
这段代码很简单,发送一条消息"Hello!“给ChatGPT,然后打印结果。
这里有3个注意事项:
-
用到了官方的openai库,需要安装
1$ pip install openai -
需要创建API key
在下面这个链接创建你的API key
-
要使用
openai.ChatCompletionopenai这个库里封装了很多类,如下所示:
其中,openai.ChatCompletion用于对话。
Role角色
细心的同学可能已经发现,给ChatGPT发送消息的时候,参数message是个数组,数组里每个dict有role这个字段。
role目前有3个取值:
-
user。表示提交prompt的一方。
-
assistant。表示给出completion响应的一方,实际上就是ChatGPT本身。
-
system。message里role为system,是为了让ChatGPT在对话过程中设定自己的行为,目前role为system的消息没有太大的实际作用,官方说法如下:
gpt-3.5-turbo-0301 does not always pay strong attention to system messages. Future models will be trained to pay stronger attention to system messages.
|
|
上面这段代码里,使用了3种角色的role,这个messages发送给ChatGPT后,ChatGPT就有了上下文,知道作为user的我们说了什么,也知道作为assistant的自己回答了什么。
想通过API实现包含上下文信息的多轮对话的关键就是用好role字段。
不含上下文的对话
|
|
上面这个实现里,每次只发送了当前输入的信息,并没有发送对话的历史记录,所以ChatGPT无法知道上下文。
我们来看对话效果如下:
|
|
包含上下文的对话
|
|
上面这个实现里,每次发送请求给ChatGPT时,把历史对话记录也一起发送,所以ChatGPT知道对话的上下文。
我们来看对话效果如下:
|
|
潜在的坑
目前通过API实现上下文对话有2个潜在的坑:
-
token数量问题。每次要把历史对话记录传过去,会导致后续单次请求和响应消耗的token数量越来越多,超过ChatGPT模型支持的最大上下文长度,ChatGPT就无法继续往下处理了。比如gpt-3.5-turbo支持的最大上下文长度是4097个token,如果单次请求和响应里包含的token数量超过这个数,ChatGPT就会返回如下错误:
This model’s maximum context length is 4097 tokens. However, you requested 4103 tokens (2066 in the messages, 2037 in the completion). Please reduce the length of the messages or completion.
-
费用问题。API是按照token数量收费的,这个token计算是prompt和completion的token数量总和。由于后续的请求包含的token数量越来越多,导致每次调用API的收费也越来越高。
那如何解决这个问题呢?
-
第一种方式就是每次发送请求时,不用带上全部历史对话记录,只带上最近几轮对话的记录。比如就带上最近6条对话记录(3条prompt,3条completion),减少单次请求里包含的token数量,避免超过ChatGPT模型的最大上下文长度。
-
第二种方式是在调用API的时候,限制用户提问内容长度,以及限制返回的completion的token数量。后者可以通过给API调用指定max_token参数来实现,该参数的含义如下:
The maximum number of tokens to generate in the chat completion.
The total length of input tokens and generated tokens is limited by the model’s context length.
总结
在官网和ChatGPT对话的同学可能会发现,API返回的completion结果其实没有官网的好。
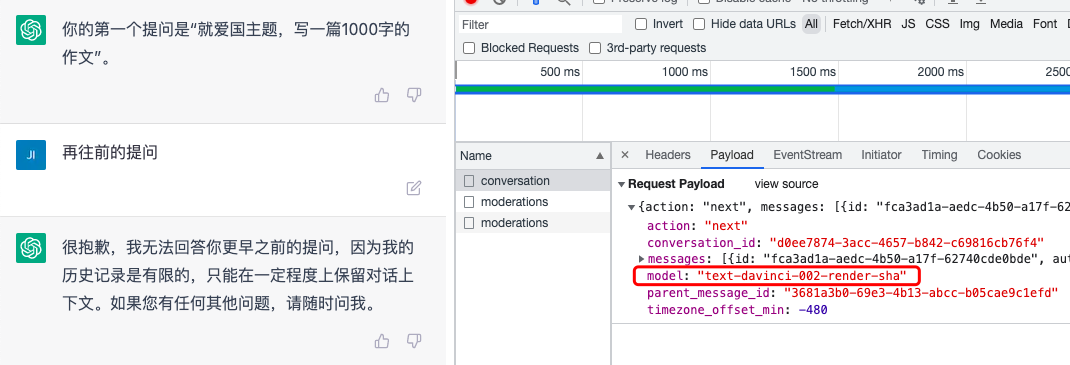
通过查看官网对话的请求信息,发现普通用户(非ChatGPT Plus会员)用的模型是text-davinci-002-render-sha,而这个模型在API里无法使用。
开源地址
想知道如何注册ChatGPT账号以及API使用教程的可以参考我的开源教程: ChatGPT模型教程。包含ChatGPT和百度文心一言的入门和实战教程。
公众号:coding进阶。
个人网站:Jincheng’s Blog。
知乎:无忌。
福利
我为大家整理了一份后端开发学习资料礼包,包含编程语言入门到进阶知识(Go、C++、Python)、后端开发技术栈、面试题等。
关注公众号「coding进阶」,发送消息 backend 领取资料礼包,这份资料会不定期更新,加入我觉得有价值的资料。还可以发送消息「进群」,和同行一起交流学习,答疑解惑。
References
